A ready-to-run example is available here!
What is a Context Condenser?
A context condenser is a crucial component that addresses one of the most persistent challenges in AI agent development: managing growing conversation context efficiently. As conversations with AI agents grow longer, the cumulative history leads to:- 💰 Increased API Costs: More tokens in the context means higher costs per API call
- ⏱️ Slower Response Times: Larger contexts take longer to process
- 📉 Reduced Effectiveness: LLMs become less effective when dealing with excessive irrelevant information
Default Implementation: LLMSummarizingCondenser
OpenHands SDK provides LLMSummarizingCondenser as the default condenser implementation. This condenser uses an LLM to generate summaries of conversation history when it exceeds the configured size limit.
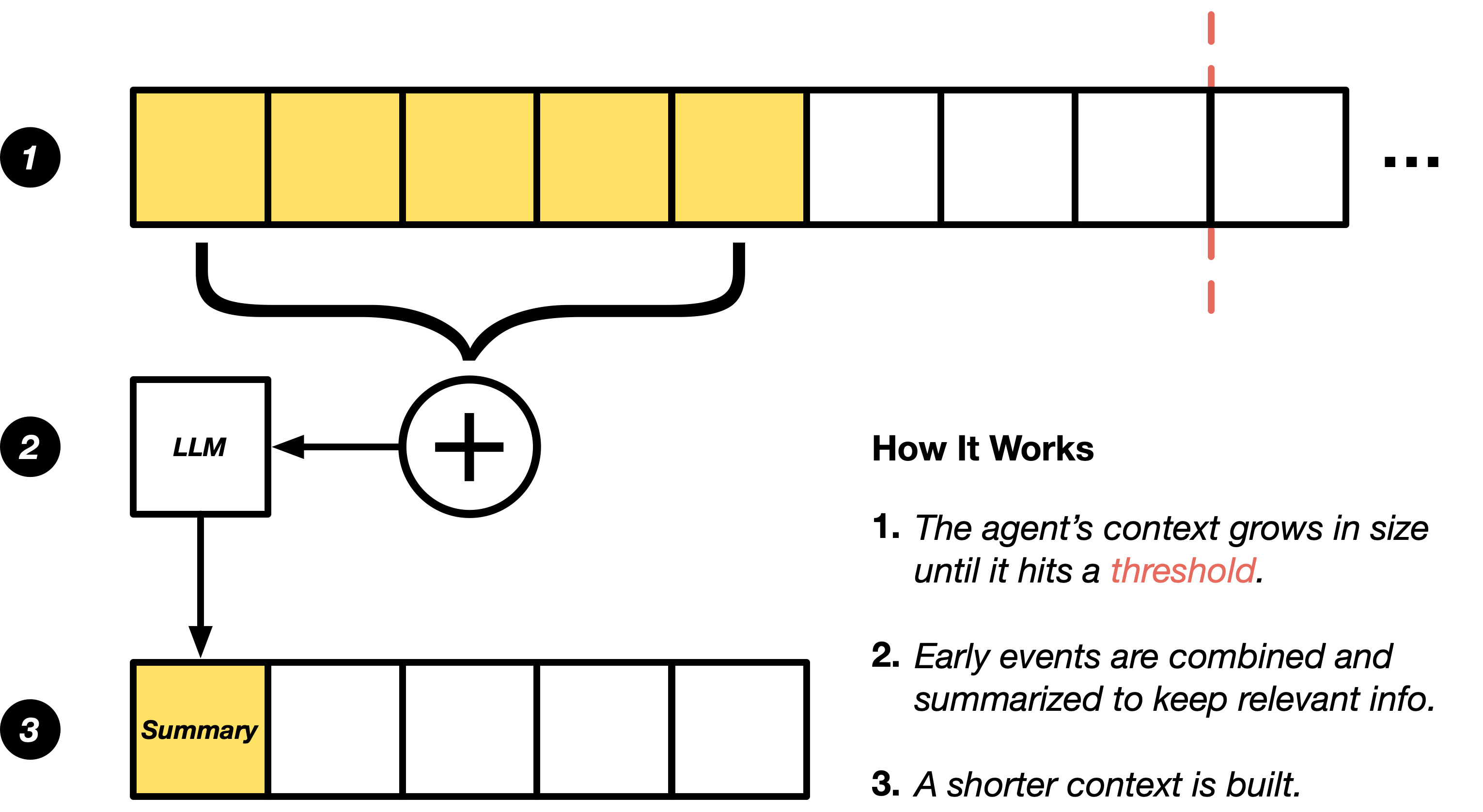
How It Works
When conversation history exceeds a defined threshold, the LLM-based condenser:- Keeps recent messages intact - The most recent exchanges remain unchanged for immediate context
- Preserves key information - Important details like user goals, technical specifications, and critical files are retained
- Summarizes older content - Earlier parts of the conversation are condensed into concise summaries using LLM-generated summaries
- Maintains continuity - The agent retains awareness of past progress without processing every historical interaction
- Up to 2x reduction in per-turn API costs
- Consistent response times even in long sessions
- Equivalent or better performance on software engineering tasks
Extensibility
TheLLMSummarizingCondenser extends the RollingCondenser base class, which provides a framework for condensers that work with rolling conversation history. You can create custom condensers by extending base classes (source code):
RollingCondenser- For condensers that apply condensation to rolling historyCondenserBase- For more specialized condensation strategies
Setting Up Condensing
Create aLLMSummarizingCondenser to manage the context.
The condenser will automatically truncate conversation history when it exceeds max_size, and replaces the dropped events with an LLM-generated summary.
This condenser triggers when there are more than max_context_length events in
the conversation history, and always keeps the first keep_first events (system prompts,
initial user messages) to preserve important context.
Ready-to-run example
This example is available on GitHub: examples/01_standalone_sdk/14_context_condenser.py
examples/01_standalone_sdk/14_context_condenser.py
The model name should follow the LiteLLM convention:
provider/model_name (e.g., anthropic/claude-sonnet-4-5-20250929, openai/gpt-4o).
The LLM_API_KEY should be the API key for your chosen provider.Next Steps
- LLM Metrics - Track token usage reduction and analyze cost savings